


本文主要为大家讲解Python用for循环读取图片,有需要的朋友可以参考一下:
下面开始一步步实现:
1.简单爬录目图片
1 import urllib.request
2 import re
3
4 def gethtml(url):
5 page=urllib.request.urlopen(url)
6 html=page.read().decode('utf-8')
7
8 return html
9
10 def getimg(html):
11
12 a=re.compile(r'src="(.+?\.jpg)"')
13 tp=a.findall(html)
14 x=0
15
16 for img in tp:
17 urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x)
18 x+=1
19
20
21 url="http://www.meituba.com/yijing/28426.html"
22
23 html=gethtml(url)
24 getimg(html)
2.爬图集
这里仅仅是爬取了录目上的图片,还没有涉及到for循环遍历,针对我们的目标,我们要尽可能仔细观察它的规律。
这里我们随便点进去一个图片集,如图:

打开后看到该图片集一共是6张,
分析一下它的url 和页面的源代码:

1,url分析
这里就不贴图片了,我直接说吧
第一张图片(也就是第一页)的url=“http://www.meituba.com/yijing/28426.html”
第二张图片的url=“http://www.meituba.com/yijing/28426_2.html”
。。。。。
第六页图片的url=“http://www.meituba.com/yijing/28426_6.html”
我们可以发现规律,这里直接改一下'_'后面的数字,这里就需要for循环了
2,源代码的规律:

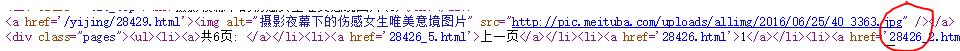
这里我们用正则表达式就应该稍作修改:
应该这样写:r'src="(.+?\.jpg)" /'
好了,下面就开始代码实现:
import urllib.request
import re
def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8')
return html
def getimg(html):
a=re.compile(r'src="(.+?\.jpg)" /')
b=a.findall(html)
for img in b:
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x)
x=0
for i in range(1,7):
if i==1:
url="http://www.meituba.com/yijing/28426.html"
else:
url=("http://www.meituba.com/yijing/28426_%s.html" % i)
html=gethtml(url)
x+=1
getimg(html)
1.这里有很多值得我们研究的问题比如第一页的url跟其他页的url有出入,所以我们应该想办法把第一页的图片也加进去,大家可以用if函数实现
看代码吧
2.关于urlretrieve()函数,在保存下载路径的时候要写出全路径,这里的
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x)
就应该做出变化了,我们可以理解一下,在第一个代码中,
我们将 x 这个函数直接定义在函数中,但那是在爬取一个网页下的所有图片,可我们的第二个代码是爬取每个页面下的一张图片,如果我们还是将 x 定义在函数中,那么就会出现一个问题,在文件夹中只会爬到一张图片
大家可以想想原因,
其实当我们用for循环遍历所有url时,getimg()函数是被一遍遍调用的,当第一个url下的图片被爬下来后,它的名称是 0.jpg 那么下一次下一个页面爬到的图片也将被命名为0.jpg
这样系统就只会默认的保存一张图片,所以我们在命名的时候应该注意这一点,
只需要将 x 的初始值定义在for循环的外面就可以了
3.一个图集的图片实在不能满足我们。
一般来说,我们可以通过观察页面url的规律来推出下一个url的地址,可我接下来观察了几个连续图集中的url的信息
28426
28429
28435
28438
28443
28445
28456
28461
本人数学不好,实在发现不了规律,其实在每个图集的下方都会给下一个图集的链接,这就给我们提供了思路,大家如果在爬取某个页面时遇到这种问题,不妨试一下
好了开始我们的代码实现了:下面仅仅是获取下个图集的url地址的代码,其余的下次补全:
import urllib.request import re from bs4 import BeautifulSoup def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8')
soup=BeautifulSoup(html,'html.parser') return soup def getimg(html):
b=html.find_all("div",{"class":"descriptionBox"})
href=re.compile(r'<b>下一篇:</b><a href="(.+?\.html)">')
c=href.findall(str(b)) print(c) print(type(c))
e="http://www.meituba.com"+('').join(c) print(e)
d=urllib.request.urlopen(e)
f=d.read().decode('utf-8') print(f)
url="http://www.meituba.com/yijing/28426.html" soup=gethtml(url)
getimg(soup)
运行可以看到它已经可以成功的打印出下一个图集的html页面源代码。
以上就是“python如何用for循环读取图片”的详细内容,请持续关注编程学习网!
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/7976/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料