

CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。
这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。
下面我们来看看,编写程序时,变量在内存中是否按内存对齐的差异。假设我们有如下结构体:
struct Foo { uint8_t a; uint32_t b; }
示意图如下:
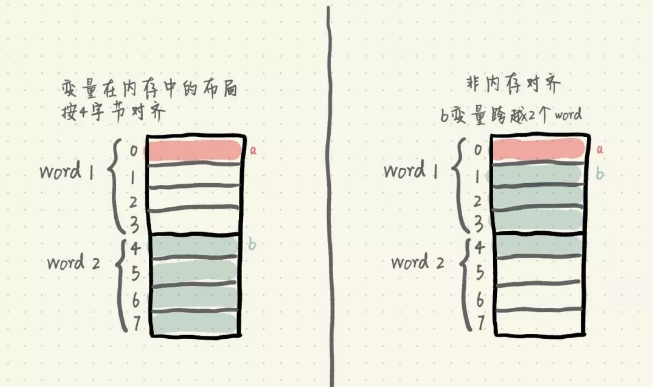
我们假设 CPU 以 4 字节为单位读取内存。
如果变量在内存中的布局按 4 字节对齐,那么读取 a 变量只需要读取一次内存,即 word1;读取 b 变量也只需要读取一次内存,即 word2。
而如果变量不做内存对齐,那么读取 a 变量也只需要读取一次内存,即 word1;但是读取 b 变量时,由于 b 变量跨越了 2 个 word,所以需要读取两次内存,分别读取 word1 和 word2 的值,然后将 word1 偏移取后 3 个字节,word2 偏移取前 1 个字节,最后将它们做或操作,拼接得到 b 变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。
另外,由于内存对齐保证了读取 b 变量是单次操作,在多核环境下,原子性更容易保证。
但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/6990/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料
查 看2022高级编程视频教程免费获取