
一个大型网站应用一般都是从最初小规模网站甚至是单机应用发展而来的,为了让系统能够支持足够大的业务量,从前端到后端也采用了各种各样技术,前端静态资源压缩整合、使用CDN、分布式SOA架构、缓存、数据库加索引、读写分离等等。这些技术是高并发系统所必须的

高并发系统设计原则
高并发的接口/系统有一个共同的特性,那就是”快”。在系统其它条件既定的情况下,系统处理请求越快,用户得到反馈的时间就越短,单位时间内服务器能够处理请求的数量就会越多。所以”快”几乎可以算是高并发系统的要满足的必要条件,要评估一个系统性能如何,某次优化是否提高系统的容量,”快”是一个很直观的衡量标准。
1. 做得少,一方面是指在功能特性上有所为,有所不为,另一方面是指一次处理的信息量要少。
2. 做得巧,根据业务自身的特点,选择合理的业务实现方式,选择合理的缓存类型和缓存调用时机。
2. 做得巧,根据业务自身的特点,选择合理的业务实现方式,选择合理的缓存类型和缓存调用时机。对于一个秒杀系统来说,瞬时的大量请求会对后台服务造成冲击,需要保证服务的可用性以及业务的正确性。
设计了一个高并发高可用的系统简要流程架构如下图:
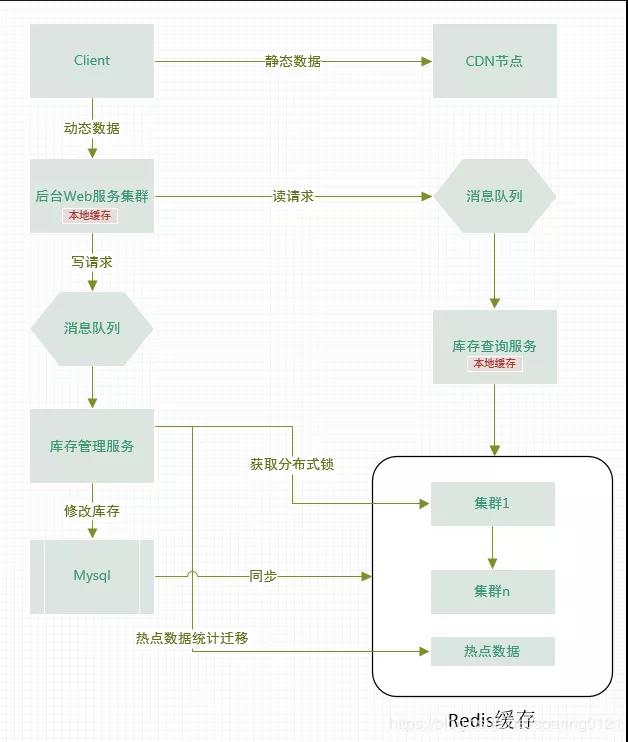
1.将商品(或券)的信息等静态数据放到cdn节点,实现动静分离
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/6532/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料
查 看2022高级编程视频教程免费获取