


那天晚上快下班了,一个小伙子跑过来跟我说: “东哥,我那个 CSV,又把服务器干冒烟了……”
我一看,他拿了个 15G 的埋点日志,用 pandas.read_csv 直接怼内存,机器 16G,读了一半开始疯狂换页,整台机子跟学狗叫一样呼哧呼哧的。那一刻我就决定——得跟你们聊聊:**别老 CSV 了,换 Parquet 吧,真的,省命。
先别急着关窗口,我用人话说下这俩玩意的区别哈。CSV 就是那种食堂打饭的长盘子,一次把所有菜都端上来,不管你吃不吃;Parquet 是点菜小碟子,你要哪几样,它就给你哪几样,其他一律不拿。
你想象一下一个 1 亿行的埋点表,你只是想看一下 user_id + event_time, CSV 的玩法是:整行读进来,然后扔掉你不要的列。 Parquet 的玩法是:磁盘上本来就是按“列”存好的,它直接只把这两列从盘里抠出来,IO 直接打骨折。
我当时给那小伙子改了个最小改动版,就两行代码,他当场沉默,过了三秒钟说了一句:“卧槽,这也太快了吧。”
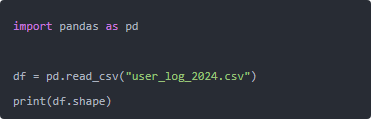
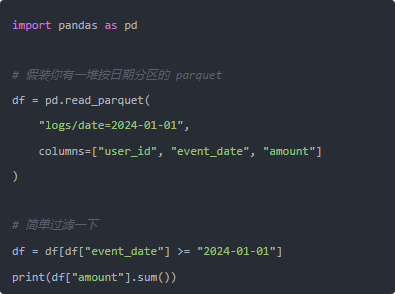
原来写法大概是这样(别学,危险动作):
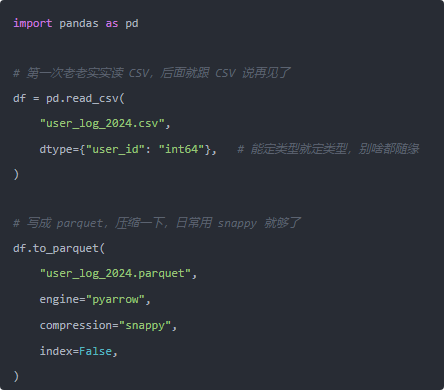
我让他先做一次格式迁移,以后都用 Parquet 玩数据:
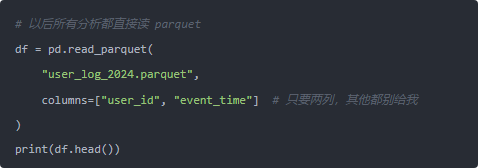
后面分析数据就换成这样:
同一台机器,同一份数据,CSV 读完要两三分钟,Parquet 几秒钟就搞定,我没掐表,但那差距,肉眼可见。
速度只是一个方面,更骚的是“轻”。
同一份数据,裸 CSV 可能 10G,写成 Parquet 开个压缩,可能就 1G 多点,甚至更小。你想想:磁盘省 90%,从网盘拉到本机也快,备份也快,连领导看监控都开心——“哎最近磁盘占用怎么下去了,是不是你们删数据了?” “没有没有,是那个…呃…算发(算法)优化了。”
再说说“安全”这一块,CSV 最大的问题就是——一切全靠缘分。
有一天你多了个布尔列 is_vip,导出来的时候变成了 "True"/"False",下游有个小哥用 read_csv,没指定 dtype,pandas 再帮你“聪明地”推断一下类型,最后你会得到一个 object 列;再有人把 "true""false""1""0" 混一起,你就会收获一个大型“玄学项目”,每次上线靠人肉盯着。
Parquet 不一样,它自带 schema。你写的时候就把类型钉死,下游谁读,都得按这个类型来,不许瞎猜。我要稍微严谨一点的时候,会这么搞:
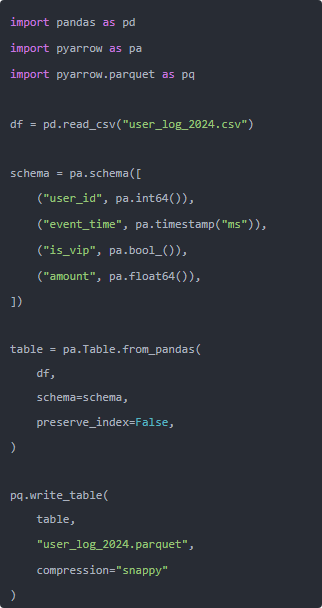
这样有什么好处? 哪天哪个同学手一抖,把 is_vip 这一列里塞了个 "哈哈" 进去,from_pandas 直接给你报错,你当场就能发现,而不是等跑了一晚上的任务才知道报表炸了。这个就叫“早点死,比晚点死舒服多了”。
而且列式存储还有一个经常被忽略的点:过滤可以在 IO 层做掉一大半。有些引擎(像 DuckDB、Polars、Spark 那一票)读 Parquet 的时候,会先把“某一列的统计信息”扫一下,比如这一块数据里 event_date 最小是 2023-01-01,最大是 2023-01-31,你的条件是 >= 2024-01-01,那这整块数据它连读都不读,直接跳过。 你想象一下,你查一个 10 亿行的表,结果磁盘只读了其中 5%,后面那 95% 连看都没看,这个性能…就不多说了。
你要是用 Python 简单玩玩,也可以先从最小版本上手,别一上来搞大数据平台,容易夸:
很多人会问一句:那我是不是以后所有东西都得换 Parquet 啊?
也别走极端,小文件、配置表、十几行的那种,CSV、甚至直接 YAML、JSON 就够了,你非得整 Parquet 反而是折腾自己。 但只要是:
- 行数多到 read_csv 要读很久的
- 字段多、只会选几列分析的
- 要在多个语言、多个系统之间互相交换的 基本上,直接上 Parquet,不用纠结。
哦对,还有一个小坑顺便提醒一句: 你要在不同语言之间互通(Python、Java、Spark 混着来),记得统一一下:
- 统一个 engine(比如都用 pyarrow)
- 统一一下时间字段的单位(ms / us / ns),不然你会看到奇怪的时间,比如“1970 年附近”满天飞,然后大家互相甩锅说是对方系统问题。
行了,差不多就说到这,我这边会议提醒已经响了三遍了…… 你要是现在手里有个大 CSV,在服务器上读着卡得要死,要不先照着上面那几段代码,悄悄转一个 parquet 试试? 等你跑完再来跟我说一句:东哥,这玩意儿,真香。
以上就是“再见CSV!Python中更快、更轻、更安全的数据处理方案:Parquet!”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/13983/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料