


前几天晚上加班,楼下便利店买了瓶冰美式,回来路上还在刷手机,一个群友在问:用 Python 匹配 HTML 标签 <g> 的时候,正则里写 <g> 和写 <g.*?> 有啥区别?我一看这问题,其实很多人都会踩坑的,就像当年我第一次用 re 模块乱写正则一样,写着写着就把整个页面都吞了。
正则匹配 <g> 和 <g.*?>
先说直白点,<g> 只会匹配完全等于<g> 这个标签开头的地方。而 <g.*?> 就不一样了,它会匹配 <g> 开头,然后加上任何属性(甚至乱七八糟的空格),直到遇到 > 为止。
举个例子:
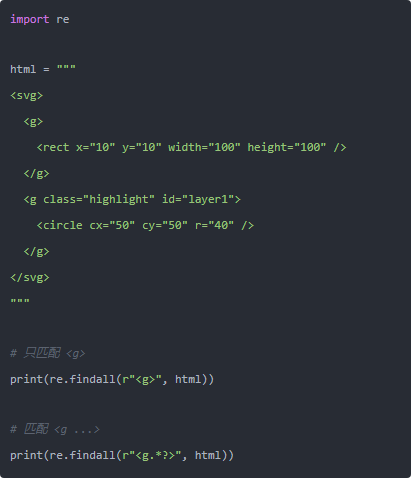
你跑一下就知道,第一个只能抓到最干净的 <g>,第二个能抓 <g> 还顺带把带属性的 <g class="highlight" id="layer1"> 一起抓出来。
为什么 .*? 特别关键
这里面的 .*? 有点绕。. 代表“任意字符”,* 代表“重复任意次”,加上 ? 就是非贪婪模式。非贪婪就是匹配到第一个 > 就收手,不然就贪得无厌,一路吃到最后一个 >,结果把整个 <g ...> ... </svg> 都吃掉了。
我当时第一次写正则忘记加 ?,写成 <g.*>,结果直接把 <g> 到最后一个 > 包括 <circle><rect> 全吃光了,调了半天发现根本不是 HTML 有问题,是我正则太蠢。
HTML 解析其实不推荐用正则
说个实话,用正则去解析 HTML 标签很容易翻车,尤其是 <g> 这种在 SVG 里常用的标签。更靠谱的方法是用解析库,比如 BeautifulSoup 或者 lxml。这样你就不用担心正则写错,直接当 DOM 来操作。
比如:
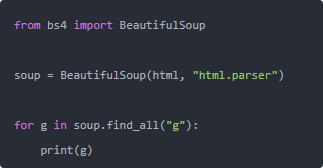
这样出来的就是 <g> 节点本身,带属性的 <g> 也不会漏。比起正则,你不用在那儿纠结 <g> 还是 <g.*?>。
那么区别总结下
但既然问题是问 <g> 和 <g.*?>,咱还是回到重点:
- <g>:只能匹配没有属性的 <g> 标签。
- <g.*?>:能匹配任何 <g> 开头的标签,包括有属性的,比如 <g id="layer1">。
所以要看你需求,如果只是想找裸 <g>,那就 <g> 就行;要包括带属性的,就得 <g.*?>。
一个小实验:提取 <g> 的内容
我写过一个脚本,需求是要把 <g> 里面的东西抽出来再单独保存。结果如果你只用 <g> 匹配,是拿不到里面东西的,你得用个分组:
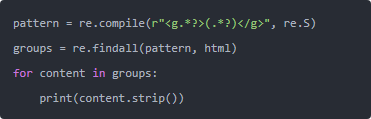
这个能把 <rect> 和 <circle> 分别抓出来。注意正则里 re.S 很关键,不然遇到换行就断掉了。
什么时候会踩坑
- 如果 HTML 里有注释 <g something> <!-- comment -->,正则很可能吃多了。
- 属性里如果有 > 字符(虽然不常见,但 SVG 的 path d="M 10 10 > 20 20" 就可能有),正则直接傻掉。
- 多层嵌套 <g>,正则更难收拾,基本废掉。
如果只是简单的替换 <g> 开头标签,那就 <g.*?>,安全点。如果你要做结构化处理,老老实实上 BeautifulSoup 或者 lxml。
差不多我就说这么多吧,昨天写到一半同事还叫我去看个接口超时的 bug,我这边正则代码都没保存好...
以上就是“用 Python 匹配 HTML g tag 的时候, 和 有什么区别?”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/13575/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料